| منوی اصلی |
 |
|
|
 تاريخ : سه شنبه 16 اردیبهشت 1404 تاريخ : سه شنبه 16 اردیبهشت 1404 |
|
|
| درباره ي سايت |
 |
|
|

تهیه پیشینه پژوهش ::
پیشینه یا سوابق پژوهشی مربوط به مساله تحقیق یکی از عناصر مهم پروپوزالهای پژوهشی و نیز تحقیقات محسوب میشود. در این قسمت به چند سوال عمده در این زمینه پاسخ میگوییم.
چرا باید پیشینه تهیه کنیم؟ جمعآوری پیشینه چه اهمیتی دارد؟ همانطور که مي دانيد، پژوهش اساساً به دنبال پاسخ سؤالات یا آزمون فرضیاتی است که در بیان مساله مطرح شده است. از آنجا که ما اولین یا تنها پژوهشگر این کرهی خاکی نیستیم!!!، همواره باید احتمال بدهیم که پژوهشگران دیگری نیز ممکن است وجود داشته باشند که به مسالهای عین یا شبیه مساله تحقیق ما پرداخته باشند. مراجعه به تحقیقات، مقالات یا کتابها و حتی مصاحبهها یا سخنرانیهای آنان میتواند پیامدهای مثبت متعددی داشته باشد که از آن جمله میتوان به موارد زیر اشاره کرد:
1- ابعاد جدیدی از مساله تحقیق را بر ما آشکار کند تا به جای تکرار بیهودهی تحقیق دیگران، تحقیق تازهای انجام دهیم.
2- به تدقیق سوالات یا فرضیات تحقیقمان کمک کند.
3- به ظرایف روش شناختی تحقیق درباره موضوع بیشتر آشنا بشویم.
4- خلاصه اینکه ما را در تجربیات محققان قبلی شریک کند و احتمال تکرار خطا در پژوهش را کاهش دهد.
اهداف ما نيزگسترش دانش و دستيابي آسان پژوهشگران ، انديشمندان ، دانشجويان و كليه علاقمندان به توسعه دانش به مقالات و پروژه هاي فارسي مي باشد تا در جهت اعتلاي دانش اين مرز و بوم سهيم باشيم
|
|
|
| موضوعات سايت |
|
|
|
|
|
| مطالب تصادفي |
|
|
|
|
|
| جستجوی پیشرفته |
|
|
|
|
|
|
| پیغام مدیر سایت |
|
|
|
|
حل تمرین دروس الکترونیک، مدارهای الکتریکی،کنترل خطی، نانوالکترونیک، فناوری ساخت مدارهای دیجیتال، ریاضیات مهندسی، معادلات دیفرانسیل، و.....
رشته مهندسی برق گرایش های الکترونیک، قدرت، کنترل، مخابرات، کامپیوتر
کاردانی، کارشناسی، کارشناسی ارشد، دکتری
از طریق تماس، واتساپ، تلگرام با شماره تلفن09372002091 وهمچنین از طریق دایرکت پیج اینستاگرام project_tehran درخواست خود را ارسال فرمایید
در سریعترین زمان و با بهترین کیفیت توسط تیم متخصص دکتری انجام می شود
*****************************************************************************
 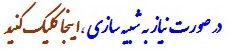
شبیه سازی پروژه و مقاله درتمام سطوح دانشگاهی پذیرفته می
شود
*****************************************************************************
 
*****************************************************************************
مامي توانيم با كمترين هزينه ودر كوتاهترين زمان ممكن در تهيه پروپزال ، پروژه ، مقاله ، پايان نامه ، گزارش كارآموزي ،به شما كمك كنيم. در صورت تمايل عنوان ومشخصات كامل مطلب درخواستي و رشته و مقطع تحصيلي و شماره همراه خود را جهت اعلام نتيجه در قسمت نظرات ثبت کنید .
ضمناْ اگر از نظر وقت عجله دارید به ایمیل یا تلگرام زیر اعلام فرمائید
ایمیل com.dr@yahoo.com
از طریق تلگرام یا واتساپ با این شماره درخواست خود را اعلام فرمایید : 09372002091
|
|
|
| جستجوی فایل ( پیشنهاد می شود جهت دسترسی سریعتر به مطلب مورد نیاز از این جستجو استفاده |
|
|
|
|
|
| جستجوی2 ( پیشنهاد می شود جهت دسترسی سریعتر به مطلب مورد نیاز از این جستجو استفاده شود ) |
|
|
|
|
|
|
|

مقاله : تکنيکهاي خوشه بندي در داده کاوي
در يک تعريف غير رسمي داده کاوي فرآيندي است، خودکار براي استخراج الگوهايي که دانش را بازنمايي مي کنند، که اين دانش به صورت ضمني در پايگاه داده هاي عظيم، انباره داده و ديگر مخازن بزرگ اطلاعات، ذخيره شده است. داده کاوي بطور همزمان از چندين رشته علمي بهره مي برد نظير: تکنولوژي پايگاه داده، هوش مصنوعي، يادگيري ماشين، شبکه هاي عصبي، آمار، شناسايي الگو، سيستم هاي مبتني بردانش ، حصول دانش ،بازيابي اطلاعات ، محاسبات سرعت بالا و بازنمايي بصري داده . داده کاوي در اواخر دهه ۱۹۸۰پديدار گشته، در دهه ۱۹۹۰ گامهاي بلندي در اين شاخه از علم برداشته شده و انتظار مي رود در اين قرن به رشد و پيشرفت خود ادامه دهد.
هدف اين گزارش فراهم کردن مطالعه اي جامع، از تکنيکهاي متفاوت خوشه بندي، در داده کاوي است. خوشه بندي, تقسيم داده ها به گروههايي از اشيا مشابه است. هر گروه، خوشه ناميده مي شود، که اشياء هر خوشه به يکديگر شبيه بوده و نسبت به اشياء ديگر خوشه ها شبيه نيستند. نمايش داده ها با تعداد خوشه هاي کم، به الزام باعث از بين رفتن جزئيات خواهد شد (شبيه از دست رفتن اطلاعات، در فشرده سازي)، اما اين کار باعث ساده سازي مسائل مي شود. تکنيک خوشه بندي، تعداد زيادي از اشياء داده اي را با تعداد کمي خوشه، نمايش مي دهد، بنابراين اين تکنيک، داده ها را با خوشه هايشان مدل مي کند. به لحاظ مدلسازي داده ها ريشه هاي ايجاد تکنيک خوشه بندي، رياضيات، آمار و آناليزعددي مي باشد. ازديدگاه يادگيري ماشين ، خوشه ها مترادف با الگوهاي مخفي ، جستجو براي يافتن خوشه ها يعني يادگيري بيسرپرست ، و سيستم حاصل بيانگر مفهوم داده ، مي باشد. بنابراين، خوشه بندي يادگيري بي سرپرست مفهوم داده مخفي، مي باشد.
داده کاوي با پايگاه داده هاي بزرگ، نيازهاي سخت محاسباتي به تکنيک آناليز خوشه ها تحميل مي کند. اين چالش و راه حل هاي ارائه شده براي آن در داده کاوي، مورد توجه اين گزارش مي باشد.
 درباره :
پایگاه داده , داده کاوی , داده کاوی , درباره :
پایگاه داده , داده کاوی , داده کاوی ,
|
|
|
|
|
|

پروژه : مفاهيم و کاربردهاي انبار داده و داده کاوي
• Bill Inmon: مجموعه اي از دادهها ي موضوع گرا، مجتمع، غيرفرار و وابسته به زمان كه براي پشتيباني از تصميم گيريها ي مديريتي مورد استفاده قرار مي گيرد
• نسخه اي از دادهها ي چند پايگاه داده، كه به منظور تسهيل پردازش و پرس و جوهاي كاربران طراحي شده است.
• يك انبار داده ،دادههاي دلخواه را از يك يا چند منبع جمع آوري كرده و آنها را به موضوعاتي با و گروههاي اطلاعاتي تبديل مي كند، سپس آنها را به همراه اطلاعات زمان و تاريخ براي پشتيباني بهتر از تصميم گيريها ذخيره مي كند، اين سيستمها ، ديدهاي متعددي از اطلاعات براي طيفها ي مختلف كاربران فراهم مي كند، قدرت اين مفهوم در آن است كه به كاربران اجازه تحليلها و پرس و جوهاي گوناگون بر روي دادهها يي مي دهد كه قبل از آن هيچ ارتباطي با هم نداشتند
• جمع آوري ، پاكسازي انتقال داده از سيستمهاي عملياتي متعدد و آماده كردن اطلاعات حاصل براي تحليل و گزارش گيري كاربران نهايي ، انبار داري دادهها ناميده مي شود.
• انبار داده پايگاه داده بزرگي است كه براي پاسخگويي به سوالات، ايجاد شده است.متناسب با انبار ، سوالات مذكور هم با هم فرق مي كنند.انبار مي تواند در اندازهها ي بزرگ (در حدود گيگابايت) يا كوچكتر باشد.كاربران انبار ممكن است كاركنان داخلي ، افراد ناشناس شبكهها و يا هر دو باشند.
• انبار داده اساس هر سيستم نرم افزاري پشتيبان تصميم گيري است و براي اخذ دادههاي DSS و كارايي بهتر پرس و جوها طراحي شده است.
• انبار داده يك پايگاه داده موضوع گرا است كه به منظور دسترسيهاي گسترده طراحي شده است. و ابزارهايي براي برآوردن نيازهاي اطلاعاتي مديران در همه سطوح سازمان آماده مي كند ، به بيان ديگر يك انبار داده به صورتي طراحي مي شود كه كاربران اطلاعات مورد نياز خود را شناسايي كنند و بتوانند با استفاده از ابزارهاي ساده اي به آنها دسترسي داشته باشند
• يك انبار داده مخزني از اطلاعات مجتمع شده است كه براي انجام پرس و جو و تحليلها آماده مي شود.................
وظيفه اصلي سيستمهاي پايگاهداده کاربردي برخط ،پشتيباني از تراکنشهاي برخط و پردازش کواِري است. اين سيستمها، سيستم پردازش تراکنش برخط(OLTP) ناميده ميشوند و بيشتر عمليات روزمره يک سازمان را پوشش ميدهند. از سوي ديگر انبارداده به کاربران يا knowledge workers خدماتي در نقش تحليلگر داده و تصميم گير نده ارائه ميکند. چنين سيستمهايي ميتوانند داده را در قالبهاي مختلف براي هماهنگ کردن نيازهاي مختلف کاربران مختلف، سازماندهي و ارائه ميکند. اين سيستمها با نام سيستمهاي پردازش تحليلي برخط (OLAP) شناختهميشوند...............
درباره :
داده کاوی , داده کاوی ,
|
|
|
|
|
|
پروژه : بررسي خوشه بند ي در داده کاوي
خوشه بندي داده، در فيلدهاي آمار، يادگيري ماشين و پايگاه داده با روشها و ديدگاههاي متفاوت مطالعه مي شود. روشهاي قبلي ارائه شده، بر پايه احتمال (بيشتر روشها در يادگيري ماشين) يا بر پايه فاصله (بيشتر روشها در آمار) مي باشند و به مساله بزرگ بودن مجموعه داده ها اهميت نداده اند. به ويژه در اين روشها مساله محدود بودن منابع (حافظه) و هزينه I/O مورد توجه نبوده است.
روشهاي برپايه احتمال: در اين روشها غالبا فرض بر اين است که توزيع احتمال بر روي ويژگيهاي مجزا بطور آماري و مستقل از هم مي باشد. البته اين فرض بسيار دور از واقعيت مي باشد. همبستگي بين ويژگيها وجود دارد و احتمال بهنگام سازي و ذخيره خوشه ها را بخصوص اگر ويژگيها داراي ارزشهاي متعدد باشند بسيار پرهزينه مي سازد. زيرا در اين حالت پيچيدگي، نه تنها بستگي به تعداد ويژگيها پيدا مي کند، بلکه به تعدد ارزش هر ويژگي نيز وابسته مي شود. از مسائل مورد توجه در اين روشها، درخت برپايه احتمال مي باشد که براي شناسايي خوشه هايي که high balanced نيستند ساخته مي شود و براي وروديهاي نامتقارت ممکن است باعث کاهش قابل توجهي در کارکرد شود.
روشهاي بر پايه فاصله: در اين روشها فرض بر اين است که تمام نقاط داده از قبل داده شده اند و مي توانند مکررا بررسي شوند. در اين روش از مساله متفاوت بودن اهميت مجموعه داده ها و اينکه نقاط داده نزديک به هم مي توانند بصورت يک مجموعه مورد بررسي قرار گيرند صرف نظر شده است. در اين روشها همواره بايد تمام نقاط، براي خوشه بندي بررسي شوند. بنابراين داراي مقياس پذيري خطي با زمان و کيفيت ثابت نمي باشند.
به عنوان مثال، با استفاده از روش شمارش، تقريبا KN/K! راه براي بخشبندي مجموعه نقاط N تايي به K زير مجموعه وجود دارد. روش بهينه سازي تکراري (IO) بايک بخش اوليه شروع مي شود. سپس در اين روش تمام نقاط قابل معاوضه از يک گروه به گروه ديگر براي بهبود ارزش تابع اندازه گيري آزمايش مي شوند. در اين روش، يافتن مينيمم محلي امکانپذير است اما کيفيت آن بر روي بخش انتخاب شده اوليه بسيار تاثيرگذار است و پيچيدگي زماني در اين روش نمايي است. در روش خوشه بندي سلسله مراتبي، بهترين خوشه ها شناسايي نمي شوند اما به مساله ادغام نزديکترين زوجها و جداسازي دورترين نقاط توجه شده است. اما پيچيدگي آن O(N2) مي باشد. بنابراين اين روش نيز با افزايش N کارا نمي باشد.
امروزه خوشه بندي، به عنوان روشي مفيد براي داده کاوي شناخته شده است. الگوريتم CLARANS بر پايه جستجوي تصادفي بوده و براي خوشه بندي آماري استفاده مي شود. در اين الگوريتم، هر خوشه با medoid مربوطه اش که داده اي است که بيش از بقيه به مرکز خوشه نزديک است ارائه مي شود. فرايند خوشه بندي بصورت جستجوي در گراف مي باشد. در اين گراف هر نود شامل k خوشه ( در واقع k ، medoid ) است. دو نود در صورتي همسايه اند که تنها در يک medoid متفاوت باشند. الگوريتم مربوطه با انتخاب يک نود به طور تصادفي شروع مي شود. و در آن شماره بزرگترين همسايه بررسي شده و اگر همسايه بهتر يافت شد به آن اضافه مي شود. در غير اين صورت نود جاري به عنوان مينيمم محلي ثبت مي شود و الگوريتم با انتخاب نود ديگري ادامه مي يابد. CLARANS پس از اينکه مينيمم محلي را يافت خاتمه مي يابد. CLARANS نيز مشکل روش IO را دارد. و ممکن است مينيمم محلي واقعي از طريق بيشرين همسايه يافته نشود. بعدها روشهايي براي بهبود کارايي CLARANS پيشنهاد شد اما آزمايشات نشان مي دهد که اين روشها زمان اجرا را بسيار ناچيز بهبود مي دهند............
امروزه، يافتن الگوهاي مفيد در مجموعه هاي داده بزرگ بسيار مورد توجه مي باشد و يکي از مسائل مهم و بسيار مورد توجه در آن شناسايي خوشه ها يا نواحي داراي جمعيت متراکم در مجموعه داده چند بعدي مي باشد. خوشه بند ي در داده کاوي براي کشف گروهها و شناسايي توزيع ها بسيار مفيد مي باشد.
در اين گزارش چهار روش مختلف براي خوشه بندي پايگاههاي داده بزرگ معرفي شده و با يکديگر و ديگر روشهاي موجود مقايسه مي شوند. به اين منظور در بخش دوم روش BIRCH شرح داده مي شود [ZRL96] و با روش پيش از خود (CLARANS [NH94]) مقايسه مي شود. اين روش، اولين الگوريتم خوشه بنديي است که نويز را نيز مديريت مي کند. سپس CURE معرفي شده [GRS98] و با الگوريتمهاي پيش از خود و BIRCH مقايسه مي شود. در بخش چهارم DBCLASD معرفي شده [XEK98] و با CLARANS و DBSCAN مقايسه مي شود. در بخش پنجم الگوريتمي موازي براي خوشه بندي سريع پايگاههاي داده بزرگ معرفي مي شود. اين الگوريتم PFDC ناميده مي شود [M02] و نسخه موازي الگوريتم FDC مي باشد. در نهايت نتايج کلي اين روشها بررسي مي شوند.
درباره :
پایگاه داده , پایگاه داده , داده کاوی , داده کاوی ,
|
|
|
|
|
|

تحقيق : بررسي وب کاوي و کاربردهاي آن
با توسعه سيستم هاي اطلاعاتي، داده به يکي از منابع پراهميت سازمان ها مبدل گشته است. بنابراين روش ها و تکنيک هايي براي دستيابي کارا به داده، اشتراک داده، استخراج اطلاعات از داده و استفاده از اين اطلاعات، مورد نياز مي باشد. با ايجاد و گسترش وب و افزايش چشمگير حجم اطلاعات، نياز به اين روش ها و تکنيک ها بيش از پيش احساس مي شود. وب، محيطي وسيع، متنوع و پويا است که کاربران متعدد اسناد خود را در آن منتشر مي کنند. در حال حاضر بيش از دو بيليون صفحه در وب موجود است و اين تعداد با نرخ 7.3 ميليون صفحه در روز افزايش مي يابد. با توجه به حجم وسيع اطلاعات در وب، مديريت آن با ابزارهاي سنتي تقريبا غير ممکن است و ابزارها و روش هايي نو براي مديريت آن مورد نياز است.......
وب کاوي يکي از زمينه هاي تحقيقاتي است که با به کارگيري تکنيک هاي داده کاوي به کشف و استخراج خودکار اطلاعات از اسناد و سرويس هاي وب مي پردازد. در واقع وب کاوي، فرآيند کشف اطلاعات و دانش ناشناخته و مفيد از داده هاي وب مي باشد. روش هاي وب کاوي بر اساس آن که چه نوع داده اي را مورد کاوش قرار مي دهند، به سه دسته کاوش محتوای وب، کاوش ساختار وب و کاوش استفاده از وب تقسيم می شوند. طي اين گزارش پس از معرفی وب کاوي و بررسی مراحل آن، ارتباط وب کاوي با ساير زمينه هاي تحقيقاتي بررسي شده و به چالش ها، مشکلات و کاربردهای اين زمينه تحقيقاتي اشاره مي شود. همچنين هر يک از انواع وب کاوي به تفصيل مورد بررسي قرار مي گيرند. براي اين منظور مدل ها، الگوريتم ها و کاربردهاي هر طبقه معرفي مي شوند.
درباره :
داده کاوی , داده کاوی ,
|
|
|
|
|
|
پايان نامه داده کاوی محيطهای توزيع شده
داده کاوی به معنای يافتن نيمه خودکار الگوهای پنهان موجود در مجموعه داده های موجود می باشد. داده کاوی از مدلهای تحليلی ، کلاس بندی و تخمين و برآورد اطلاعات و ارائه نتايج با استفاده از ابزارهای مربوطه بهره می گيرد. می توان گفت که داده کاوی در جهت کشف اطلاعات پنهان و روابط موجود در بين داده های فعلی و پيش¬بينی موارد نامعلوم و يا مشاهده نشده عمل می¬کند. برای انجام عمليات داده¬کاوی لازم است قبلا روی داده های موجود پيش پردازشهايی انجام گيرد. عمل پيش پردازش اطلاعات خود از دو بخش کاهش اطلاعات و خلاصه¬سازی و کلی سازی داده ها تشکيل شده است. کاهش اطلاعات عبارت است از توليد يک مجموعه کوچکتر، از داده های اوليه، که تحت عمليات داده کاوی نتايج تقريبا يکسانی با نتايج داده کاوی روی اطلاعات اوليه به دست دهد. پس از انجام عمل کاهش اطلاعات و حذف خصايص غير مرتبط نوبت به خلاصه سازی و کلی سازی داده ها می رسد. داده های موجود در بانک¬های اطلاعاتی معمولا حاوی اطلاعات در سطوح پايينی هستند، بنابراين خلاصه¬سازی مجموعه بزرگی از داده ها و ارائه آن به صورت يک مفهوم کلی اهميت بسيار زيادی دارد. کلی¬سازی اطلاعات، فرآيندی است که تعداد زيادی از رکوردهای يک بانک اطلاعاتی را به صورت مفهومی در سطح بالاتر ارائه می نمايد. خود روشهای داده کاوی به سه دسته کلی تقسيم می شوند که عبارتند از خوشه¬بندی، طبقه¬بندی و کشف قواعد وابستگی. در ادامه هر يک از اين روشها را بطور کلی معرفی می نماييم........................
درباره :
داده کاوی ,
|
|
|
|
|
|
مقاله : ایجاد یک پایگاه داده بوسيله XML
مقدمه
XML امروزه بعنوان یکی از کاربردی ترین روشهای حفظ و انتقال داده ها به شمار می رود. فرمت ساده آن، متنی بودن و همخوان بودن با سایر استانداردها، نرم افزارهای کاربردی امروزی و آینده را بیش از پیش به سوی خود سوق می دهد. در دنیای برنامه های تحت وب XML بعنوان یکی از روان ترین و ساده ترین روشها برای حفظ اطلاعات و یا انتقال اطلاعات ( WebSrvices ) بکار می رود. امروزه اکثر سایتهای اینترنتی بویژه آنها که برپایه NET. بنا شده اند، برای آندسته از داده های دینامیکی خود که رکوردهای نه چندان زیادی را شامل می شوند از XML استفاده می کنند.
به XML به عنوان یک پلیگاه داده نیز می توان نگریست. در یک فایل XML بمانند سایر پایگاههای داده نظیر SQL Server ، Access و ... می توان براحتی بر روی رکوردهای خاص Query گرفت و یا داده های موجود را اصلاح کرد. سعی بر آن است تا استفاده از XML بعنوان پایگاه داده بصورت بسیار ساده ای مورد بحث قرار گیرد در این مقاله به ایجاد فایل XML در محیط VS.NET می پردازیم. برای این منظور از منوی File گزینه New و بعد File را انتخاب کنید. به این ترتیب یک فایل XML خالی در اختیار شما قرار می گیرد. در اینجا می بایست پایگاه داده مان را نامگذاری کنیم. برای این منظور یک المان با نام دلخواه به آن اضافه می کنیم در اینجا نام پایگاه داده را DataBook می گذاریم به صورت زیر عمل می کنیم............
درباره :
پایگاه داده , پایگاه داده , داده کاوی , داده کاوی ,
برچسب ها :
XML , پایگاه داده بوسيله XML , فایل XML , WebSrvices , NET , Query ,
|
|
|
|
|
|

مقاله : وب كاويWeb Mining ( پاورپوينت )
مقاله
ظهور وب جهاني (WWW) کاربران کامپيوتر خانگي را با جرياني وحشتناک از اطلاعات مواجه کرده است. تقريباً هر موضوعي مي تواند بياد آورده شود , يکي مي تواند تکه هاي اطلاعات را که توسط ديگر شهروندان اينترنت قابل دسترس مي شوند را پيدا کند, تنظيم کردن کاربران شخصي که ليستي از مجموعه رکورد هايشان را , براي شرکت هاي خاص که در وب تجارت مي کنند مي فرستند........
درباره :
پایگاه داده , داده کاوی , داده کاوی ,
|
|
|
|
|
|
مقاله : مقدمه ای بر داده كاوي
چکیده
در حال حاضر فناوری های زیادی برای جمع آوری و ذخیره ی داده ها وجود دارند که منجر به تولید حجم عظیمی از داده ها و رشد سریع هر ساله ی آن ها می شود. سیستم های پایگاه داده با فراهم کردن ابزارها و محیط های لازم، بستر لازم برای مدیریت و دسترسی سیستماتیک و موثر به این حجم از داده را تسهیل کرده اند. اما استخراج دانش از پایگاه های داده بدون استفاده از کامپیوتر و بکارگیری ابزارهای تحلیلی قدرتمند و خودکار کاری بسیار دشوار و شاید غیرممکن است. وجود چنین ابزارهایی فاصله ی چشمگیر موجود میان تولید داده و فهم آن را کاهش داده و راه های کشف الگوهای مفید از پایگاه های داده را که در عرصه های گوناگون علمی، تحقیقی و تجاری مورد توجه است، هموارتر می سازد. در حال حاضر ابزارها و تکنیک های زیادی برای رسیدن به این هدف پیشنهاد شده اند که همگی تحت عنوان کلّی داده کاوی مطرح می شوند. در این گزارش هدف ما معرفی اجمالی حوزه های مختلف داده کاوی است و از این میان تمرکز بیشتری بر روی دو حوزه ی رده بندی و خوشه بندی داده ها خواهیم داشت.
درباره :
داده کاوی , داده کاوی ,
|
|
|
|
|
|
مقاله : بررسی نويز و نحوه رويکرد با آن در داده کاوي
چكيده :
روشهاي قديمي داده کاوي شامل گستره وسيعي از ابزار و تکنيک ها بوده که براي آناليز پايگاه هاي داده خيلي بزرگ در جهت کشف دانشهاي مفيد و همچنين دانشهايي که قبلاً مجهول بوده در داخل داده ها نهفته مورد استفاده قرار مي گيرد. در اکثر اين روشها فرض بر اين است که پايگاه داده هاي موجود در ابعاد مناسب مي باشد و نسبتاً بدون نويز مي باشد. يعني شرايط ايده آل براي داده کاوي کاملاً مهيا مي باشد البته گاهي اوقات که داده ها داراي نويز مي بود پاکسازي داده ها نيز براي حذف يا تصحيح بخشهاي نسبتاً کوچکي از اطلاعات که داراي مقادير اشتباه مي باشد يا داده هايي که داراي تناقض هستند بکار مي رفت. بعبارت ديگر در برخورد با داده هاي خطا و يا ناقص آن داده ها حذف مي گرديد و آموزش با بعقيه داده هاي موجود بکار گرفته مي شد که البته اين روش مناسب نيست زيرا ممکن است داده هاي حذف شده داده هاي مهمي باشد و تاثير زيادي در آموزش صحيح داشته باشد يا اينکه حتي داده هاي باقيمانده در اثر حذف داده.............در اين تحقيق ايده اي براي داده کاوي در مورد پايگاه هاي داده نويزي که ممکن است توسط سيستم هاي آموزش ماشين ساخته شده باشد توضيح داده مي شود. همچنين روشهايي براي تخمين توزيع احتمال پيوسته بدون نويز در حالتي که نويز مشاهده مي شود. و همچنين احتمال شرطي ، که مي تواند با استفاده از نمونه هاي آماري و آناليز خطا تخمين زده شود بررسي مي شود و همچنين آزمايشات مختلفي براي تست اين ايده ها ارائه شده است توضيح داده مي شود. در قسمت بعد الگوريتمهايي براي آموزش نويزي از جمله الگوريتم PAC ارائه مي گردد و در مورد توسعه آن نيز بحث مي شود که تحت دو الگوريتم يادگيري ضعيف و قوي که قابل تعميم به يکديگر هستند مورد بررسي قرار مي گيرد. در نهايت کاربردي از داده کاوي در محيط نويزي از جمله روشهايي داده کاوي در محيطهای نويزی برای از بين بردن نويز در صفحات وب بحث مي گردد
درباره :
داده کاوی , داده کاوی ,
|
|
|
|
|
|
مقاله : یکپارچه سازی داده کاوی در پایگاه داده
Integration of DataMining and Relational Databases
چكيده :
سالهای اخیر نشان داده است که تحلیل داده تنها با استفاده از ابزارهای OLAP مشکل شده است. تکنیک های داده کاوی خصوصا در کاربردشان در پایگاه داده های واقعی زیاد مطالعه شده است. این تکنیک ها اغلب به صورت تکراری کل مجموعه را پویش میکند. همچنین وعده سیستمهای پشتیبانی تصمیم، بهره برداری از داده های تجاری برای بدست آوردن سود بیشتر در رقابت با دیگر سیستمها می باشد . سالهای اخیر نیاز به یک فرایند خودکار برای کشف الگوهای جالب و پنهان در پایگاه داده های واقعی و دستکاری حجم زیادی از داده ها بوجود آمده است. این فرایند داده کاوی با الگوریتمهای بسیاری برای عملیات موردنظر همراه است و این الگوریتم ها باید قابلیت مقیاس پذیری بر روی مجموعه داده های بزرگ جهت اجرای کارا را داشته باشند. از اینرو طراحان پایگاه داده ها تصمیم به ارائه روشهایی برای یکپارچه سازی عملیات داده کاوی در پایگاه داده شدند.......
درباره :
داده کاوی , داده کاوی ,
|
|
|
|
|
|

مقاله : بررسي کاربردهای داده کاوی در مدیریت کتابخانه ها و موسسات آموزشی
چكيده :
پیشرفتهای حاصله در علم اطلاع رسانی و تکنولوژی اطلاعات، فنون و ابزارهای جدیدی برای غلبه بر رشد مستمر و تنوع بانکهای اطلاعاتی تامین می کنند. این پیشرفتها هم در بعد سخت افزاری و هم نرم افزاری حاصل شده اند. ریزپردازنده های سریع، ابزارهای ذخیره داده های انبوه پیوسته و غیر پیوسته، اسکنرها، چاپگرها و دیگر ابزارهای جانبی نمایانگر پیشرفتهای حوزه سخت افزار هستند. پیشرفتهای حاصل در نظامهای مدیریت بانک اطلاعات در طی چهار دهه گذشته نمایانگر تلاشهای بخش نرم افزاری است. این تلاشها در بخش نرم افزار را میتوان بعنوان یک حرکت پیشرونده از ایجاد یک بانک اطلاعات ساده تا شبکه ها و بانکهای اطلاعاتی رابطه ای و سلسله مراتبی برای پاسخگویی به نیاز روزافزون سازماندهی و بازیابی اطلاعات ملاحظه نمود. بدین منظور در هر دوره، نظامهای مدیریت بانک اطلاعاتی مناسب سازگار با نرم افزار سیستم عامل و سخت افزار رایج گسترش یافته اند. در این رابطه میتوان از محصولاتی مانند، Dbase-IV, Unify, Sybase, Oracle و غیره نام برد.
داده کاوی یکی از پیشرفتهای اخیر در راستای فن آوریهای مدیریت داده هاست. داده کاوی مجموعه ای از فنون است که به شخص امکان میدهد تا ورای داده پردازی معمولی حرکت کند و به استخراج اطلاعاتی که در انبوه داده ها مخفی و یا پنهان است کمک می کند. انگیزه برای گسترش داده کاوی بطور عمده از دنیای تجارت در دهه 1990 پدید آمد. مثلا داده کاوی در حوزه بازاریابی، بدلیل پیوستگی غیرقابل انتظاری که بین پروفایل یک مشتری و الگوی خرید او ایجاد میکند اهمیتی خاص دارد. تحلیل رکوردهای حجیم نگهداری سخت افزارهای صنعتی، داده های هواشناسی و دیدن کانالهای تلوزیونی از دیگر کاربردهای آن است. در حوزه مدیریت کتابخانه کاربرد داده کاوی بعنوان فرایند ماخذ کاوی نامگذاری شده است. این مقاله به کاربردهای داده کاوی در مدیریت کتابخانه ها و موسسات آموزشی می پردازد. در ابتدا به چند سیستم سازماندهی داده ها که ارتباط نزدیکی به داده کاوی دارند می پردازد؛ سپس عناصر داده ای توصیف میشوند و درپایان چگونگی بکارگیری داده کاوی در کتابخانه ها و موسسات آموزشی مورد بحث قرار گرفته و مسائل عملی مرتبط در نظر گرفته می شوند.
درباره :
داده کاوی , داده کاوی ,
|
|
|
|
|
|
مقاله : بررسی و تحليل وب کاوی
مقدمه :
با توسعه سيستم هاي اطلاعاتي، داده به يکي از منابع پراهميت سازمان ها مبدل گشته است. بنابراين روش ها و تکنيک هايي براي دستيابي کارا به داده، اشتراک داده، استخراج اطلاعات از داده و استفاده از اين اطلاعات، مورد نياز مي باشد. با ايجاد و گسترش وب و افزايش چشمگير حجم اطلاعات، نياز به اين روش ها و تکنيک ها بيش از پيش احساس مي شود. وب، محيطي وسيع، متنوع و پويا است که کاربران متعدد اسناد خود را در آن منتشر مي کنند. در حال حاضر بيش از دو بيليون صفحه در وب موجود است و اين تعداد با نرخ 7.3 ميليون صفحه در روز افزايش مي يابد. با توجه به حجم وسيع اطلاعات در وب، مديريت آن با ابزارهاي سنتي تقريبا غير ممکن است و ابزارها و روش هايي نو براي مديريت آن مورد نياز است...........
با افزايش چشمگير حجم اطلاعات و توسعه وب، نياز به روش ها و تکنيک هايي که بتوانند امکان دستيابي کارا به داده ها و استخراج اطلاعات از آنها را فراهم کنند، بيش از پيش احساس مي شود. وب کاوي يکي از زمينه هاي تحقيقاتي است که با به کارگيري تکنيک هاي داده کاوي به کشف و استخراج خودکار اطلاعات از اسناد و سرويس هاي وب مي پردازد. در واقع وب کاوي، فرآيند کشف اطلاعات و دانش ناشناخته و مفيد از داده هاي وب مي باشد. روش هاي وب کاوي بر اساس آن که چه نوع داده اي را مورد کاوش قرار مي دهند، به سه دسته کاوش محتوای وب، کاوش ساختار وب و کاوش استفاده از وب تقسيم می شوند. طي اين گزارش پس از معرفی وب کاوي و بررسی مراحل آن، ارتباط وب کاوي با ساير زمينه هاي تحقيقاتي بررسي شده و به چالش ها، مشکلات و کاربردهای اين زمينه تحقيقاتي اشاره مي شود. همچنين هر يک از انواع وب کاوي به تفصيل مورد بررسي قرار مي گيرند. براي اين منظور مدل ها، الگوريتم ها و کاربردهاي هر طبقه معرفي مي شوند
درباره :
داده کاوی , داده کاوی ,
|
|
|
|
|
|
مقاله : داده کاوي، مفهوم و کاربرد آن در آموزش عالي
مقدمه
از هنگامي که رايانه در تحليل و ذخيره سازي داده ها بکار رفت (1950) پس از حدود 20 سال، حجم داده ها در پايگاه داده ها دو برابر شد. ولي پس از گذشت دو دهه و همزمان با پيشرفت فن آوري اطلاعات(IT) هر دو سال يکبار حجم داده ها، دو برابر شد. همچنين تعداد پايگاه داده ها با سرعت بيشتري رشد نمود. اين در حالي است که تعداد متخصصين تحليل داده ها و آمارشناسان با اين سرعت رشد نكرد. حتي اگر چنين امري اتفاق مي افتاد، بسياري از پايگاه داده ها چنان گسترش يافته اند که شامل چندصد ميليون يا چندصد ميليارد رکورد ثبت شده هستند و امکان تحليل و استخراج اطلاعات با روش هاي معمول آماري از دل انبوه داده ها مستلزم چند روز کار با رايانه- هاي موجود است. حال با وجود سيستم هاي يکپارچه اطلاعاتي، سيستم هاي يکپارچه بانکي و تجارت الکترونيک، لحظه به لحظه به حجم داده ها در پايگاه داده هاي مربوط اضافه شده و باعث به وجود آمدن انبارهاي ( توده هاي ) عظيمي از داده ها شده است به طوري که ضرورت کشف و استخراج سريع و دقيق دانش از اين پايگاه داده ها را بيش از پيش نمايان کرده است (چنان که در عصر حاضر گفته مي شود « اطلاعات طلاست» ).
هم اکنون در هر کشور، سازمان ها، شرکت ها و . . . براي امور بازرگاني، پرسنلي، آموزشي، آماري و . . . پايگاه داده ها ايجاد يا خريداري شده است، به طوري که اين پايگاه داده ها براي مديران، برنامه ريزان، پژوهشگران و . . . جهت تصميم گيري هاي راهبردي، تهيه گزارش هاي مختلف، توصيف وضعيت جاري خود و . . . مي تواند مفيد باشد. داده کاوي يا استخراج و کشف سريع و دقيق اطلاعات با ارزش و پنهان از اين پايگاه داده ها از جمله اموري است که هر کشور، سازمان و شرکتي به منظور توسعه علمي، فني و اقتصادي خود به آن نياز دارد.
در کشور ما نيز سازمان ها، شرکت ها و مؤسسات دولتي و خصوصي به طور فزاينده ولي آهسته در حال ايجاد يا خريد نرم افزارهاي پايگاه داده ها و مکانيزه کردن سيستم هاي اطلاعات خود هستند، همچنين با توجه به فصول دهم و يازدهم قانون برنامه سوم توسعه در خصوص داد و ستدهاي الکترونيکي و همچنين تأکيد بر برخورداري کشور از فن آوري هاي جديد اطلاعات براي دستيابي آسان به اطلاعات داخلي و خارجي، دولت مکلف شده است امکانات لازم براي دستيابي آسان به اطلاعات، زمينه سازي براي اتصال کشور به شبکه هاي جهاني و ايجاد زير ساخت هاي ارتباطي و شاهراه هاي اطلاعاتي فراهم کند. واضح است اين امر باعث ايجاد پايگاه هاي عظيم داده ها شده و ضرورت استفاده از داده کاوي را بيش از پيش نمايان مي سازد.
درباره :
تکنیکها ، ابزارها و روشهای Web Data Mining , داده کاوی , داده کاوی ,
|
|
|
|
|
|

پايان نامه : بررسي كاربرد داده كاوي در زمينه مرتبط با حوزه ي مهندسي كامپيوتر
درباره :
داده کاوی ,
|
|
|
|
|
|
پايان نامه : تکنیکها ، ابزارها و روشهای Web Data Mining
پيشگفتار :
در عصر حاضر Web Mining محیط اینترنت جهانی را تبدیل به محیطی کاربردی تر کرده است.که کاربران میتوانند سریعتر و راحتتر اطلاعات مورد نیازشان را پیدا کنند که شامل :کشف و تحلیل داده ، مستندات وmulti media از محیط اینترنت جهانی میباشد.Web Mining از جزئیات سند ومحتویات سند و ساختار Hyper Link برای کمک به کاربر جهت مشاهده اطلاعات مورد نیازش استفاده میکند.وب و موتورهای جستجو خودشان شامل اطلاعات ارتباطی درباره ی مستندات هستند و Web Mining این ارتباطات را کشف میکندو به سه بخش تقسیم بندی مینماید.در اولین بخش Web Content Mining، موتورهای جستجو محتویات را با کلمات کلیدی تعریف میکنندومی شناسند.پیدا کردن کلمات کلیدی محتوا و پیدا کردن یک ارتباط بین محتوای صفحه ی وب و محتوای سوال کاربر، Content Mining گفته میشود.
Hyper Links اطلاعاتی را درباره ی سایر مستندات روی وب کهخ در سند دیگری مهم هستند تهیه میکند.این لینکها عمقی را به سند اضافه میکنند و حالت چند بعدی که از خصوصیات وب است ایجاد میکنند. کاوش این ساختار لینک دومین بخش یعنی Web Structure Mining است. در نهایت ارتباطی با سایر مستندات روی وب که بوسیله ی جستجوی قبلی شناخته شده اند، وجود دارد. این ارتباط در صفحه های جستجو (log) و دستیابی ذخیره میشود. کاوش این Log ها سومین بخش یعنی Web Usage Mining را تشکیل میدهد.درک کاربر اغلب یک بخش مهم از Web Mining است. تحلیل جستجوهای قبلی کاربر ،شکلی که کاربر ترجیح میدهد اطلاعات پیدا شده را ببیندو سرعت در پاسخ ممکن است در پاسخ دادن به پرس و جوی کاربر موثر باشد.
Web Mining در ماهیت نظم خاصی دارد.پل زدن بین فیلدهایی مثل اطلاعات بازگشتی ، چردازش زبانهای طبیعی، استخراج اطلاعات ،Machine Learning، پایگاه داده ،داده کاوی ،ذخیره ی داده ، طراحی رابط کاربر و Visual کردن .تکنیکهای Web Mining کاربردهای عملی در M-commerce ،E-commerce ،
E-Government ،E-learning ، آموزش از راه دور ، آموزش سازمانی،تشکیلات مجازی ، مدیریت دانش و کتابخانه ی دیجیتال دارد.در این تحقیق ما به بررسی جنبه های مختلف Web Data Mining میپردازیم.
درباره :
ساخت پایگاه دانش , تکنیکها ، ابزارها و روشهای Web Data Mining , پایگاه داده , داده کاوی ,
|
|
|
|
|
|

پايان نامه : تکنیک های داده کاوی در سازمانها (Data Mining )
چكيده:
در دو دهه قبل تو انايي های فنی بشر در برای توليد و جمع آوری دادهها به سرعت افزايش يافته است. عواملی نظير استفاده گسترده از بارکد برای توليدات تجاری، به خدمت گرفتن کامپيوتر در کسب و کار، علوم، خدمات دولتی و پيشرفت در وسائل جمع آوری داده، از اسکن کردن متون و تصاوير تا سيستمهای سنجش از دور ماهواره ای، در اين تغييرات نقش مهمی دارند.
بطور کلی استفاده همگانی از وب و اينترنت به عنوان يک سيستم اطلاع رسانی جهانی ما را مواجه با حجم زیادی از داده و اطلاعات میکند. اين رشد انفجاری در دادههای ذخيره شده، نياز مبرم وجود تکنولوژی های جديد و ابزارهای خودکاری را ايجاد کرده که به صورت هوشمند به انسان ياری رسانند تا اين حجم زياد داده را به اطلاعات و دانش تبديل کند: داده کاوی به عنوان يک راه حل برای اين مسائل مطرح مي باشد. در يک تعريف غير رسمی داده کاوی فرآيندی است، خودکار برای استخراج الگوهايی که دانش را بازنمايی مي کنند، که اين دانش به صورت ضمنی در پايگاه داده های عظيم، انباره داده و ديگر مخازن بزرگ اطلاعات، ذخيره شده است. داده کاوی بطور همزمان از چندين رشته علمی بهره مي برد نظير: تکنولوژی پايگاه داده، هوش مصنوعی، يادگيری ماشين، شبکه های عصبی، آمار، شناسايی الگو، سيستم های مبتنی بر دانش ، حصول دانش ، بازيابی اطلاعات ، محاسبات سرعت بالا و بازنمايی بصری داده . داده کاوی در اواخر دهه 1980 پديدار گشته، در دهه 1990 گامهای بلندی در اين شاخه از علم برداشته شده و انتظار می رود در اين قرن به رشد و پيشرفت خود ادامه دهد.
واژه های «داده کاوی» و «کشف دانش در پایگاه داده» اغلب به صورت مترادف یکدیگر مورد استفاده قرار می گیرند. کشف دانش به عنوان يک فرآيند در شکل1-1 نشان داده شده است.
کشف دانش در پایگاه داده فرایند شناسایی درست، ساده، مفید، و نهایتا الگوها و مدلهای قابل فهم در داده ها می باشد. داده کاوی، مرحله ای از فرایند کشف دانش می باشد و شامل الگوریتمهای مخصوص داده کاوی است، بطوریکه، تحت محدودیتهای مؤثر محاسباتی قابل قبول، الگوها و یا مدلها را در داده کشف می کند، به بیان ساده تر، داده کاوی به فرایند استخراج دانش ناشناخته، درست، و بالقوه مفید از داده اطلاق می شود. تعریف دیگر اینست که، داده کاوی گونه ای از تکنیکها برای شناسایی اطلاعات و یا دانش تصمیم گیری از قطعات داده می باشد، به نحوی که با استخراج آنها، در حوزه های تصمیم گیری، پیش بینی، پیشگویی، و تخمین مورد استفاده قرار گیرند. داده ها اغلب حجیم ، اما بدون ارزش می باشند، داده به تنهایی قابل استفاده نیست، بلکه دانش نهفته در داده ها قابل استفاده می باشد. به این دلیل اغلب به داده کاوی، تحلیل داده ای ثانویه گفته می شود.............................
داده کاوی، استخراج اطلاعات و دانش و کشف الگوهای پنهان از یک پایگاه داده های بسیار بزرگ، کاربردهای زیادی در کسب و کارهای امروزی پیدا کرده است. استفاده از تکنیک های داده کاوی در سازمان ها منتج به تعداد زیادی قانون و الگو می شود که با توجه به محدودیت در منابع و بودجه، پیاده سازی همه ی آنها امکان پذیر نمی باشد. می توان گفت که ارزیابی و رتبه بندی قوانین وابستگی کاری مهم و چالش برانگیز است. با استفاده از از تكنيك ناپارامتريك تحليل پوششي داده ها به ارائه چارچوبي براي ارزيابي و اولويت بندي قوانين وابستگي مي پردازيم. در اين تحقيق ابتدا مدلي براي شناسايي كاراترين واحد تصميم گيري در حالت بازده متغير به مقياس ارائه مي شود. پس از آن، با استفاده اين مدل، متدي نوين جهت رتبه بندي واحدهاي تصميم گيري ارائه مي شود. سپس با استفاده از مدل و متد پيشنهادي، چارچوبي نوين جهت رتبه بندي قوانين وابستگي داده كاوي توسعه داده مي شود. در انتها، با پياده سازي چارچوب پيشنهادي براي اولويت بندي قوانين وابستگي داده كاوي در بانك كشاورزي كاربردپذيري چارچوب پيشنهادي نشان داده مي شود.
درباره :
داده کاوی ,
|
|
|
|
|
| آمار کاربران |
|
|
|
|
|
| عضويت سريع |
|
|
|
|
|
| دانلود فونت هاي كاربردي |
|
|
|
دريافت Download ( Farsi Fonts - Arabic Fonts ) Font
| نام فايل | اسم فونت | اسم فونت | | ARABICS.TTF | Arabic Style | عربيک استايل | | ARSHIA.TTF | Arshia | ارشيا | | BADR.TTF | Badr | بدر | | BADRB.TTF | Badr Bold | بدر بولد | | BSEPEHR.TTF | Sepehr | سپهر | | COMPSET.TTF | Compset | کامپ ست | | COMPSETB.TTF | Compset Bold | کامپ ست بولد | | ELHAM.TTF | Elham | الهام | | FANTEZY.TTF | Fantezy | فانتزي | | FARNAZ.TTF | Farnaz | فرناز | | FERDOSI.TTF | Ferdosi | فردوسي | | HOMA.TTF | Homa | هما | | IranNastaliq.ttf | Iran Nastaliq | ايران نستعليق | | JADIDB.TTF | Jadid Bold | جديد بولد | | KAMRAN.TTF | Kamran | کامران | | KAMRANB.TTF | Kamran Bold | کامران بولد | | KOODAKB.TTF | Koodak Bold | کودک بولد | | LOTUS.TTF | Lotus | لوتوس | | LOTUSB.TTF | Lotus Bold | لوتوس بولد | | MAJIDSH.TTF | Majid shadow | مجيد شدو | | MITRA.TTF | Mitra | ميترا | | MITRAB.TTF | Mitra Bold | ميترا بولد | | NASIMB.TTF | Nasim Bold | نسيم بولد | | NAZANIN.TTF | Nazanin | نازنين | | NAZANINB.TTF | Nazanin Bold | نازنين بولد | | PERSIAN.TTF | Pershian Nimrooz | پرشين نيمروز | | Persweb.ttf | Persian Web | پرشين وب | | PFONT.TTF | Persian Font | پرشين فونت | | ROYA.TTF | Roya | رويا | | ROYAB.TTF | Roya Bold | رويا بولد | | SEPEHR.TTF | Sepehr | سپهر | | SINAB.TTF | Sina Bold | سينا بولد | | TABASSOM.TTF | Tabassom | تبسم | | TITRB.TTF | Titr Bold | تيتر بولد | | TRAFFIC.TTF | Teraffic | ترافيک | | TRAFFICB.TTF | Teraffic Bold | ترافيک بولد | | YAGUT.TTF | Yagut | ياقوت | | YAGUTB.TTF | Yagut Bold | ياقوت بولد | | ZAR.TTF | Zar | زر | | ZARB.TTF | Zar Bold | زر بولد |
|
|
|
| مطالب محبوب |
|
|
|
|
|
| خبرنامه |
|
|
|
برای اطلاع از آپیدت شدن وبلاگ در خبرنامه وبلاگ عضو شوید تا جدیدترین مطالب به ایمیل شما ارسال شود
 لطفا صبر کنید ...
|
|
|
| پيوند هاي روانه |
|
|
|
|
|
| لینک دوستان |
|
|
|
|
|
| فالنامه |
|
|
|
|
|
|

 پایان نامه و پروژه های رشته برق
پایان نامه و پروژه های رشته برق